소프트웨어 신뢰성 측정 프로세스는 크게 두 부분으로 구성된다.
- 신뢰성에 영향을 미치는 프로세스의 특성, 산출물의 특성을 나타내는 측정치와 시험 단계에서 나오는 결함 정보를 수집하는 과정
- 수집된 정보를 분석하여 현재의 신뢰성과 미래의 신뢰성를 추정 및 예측하는 과정
1. 정보 수집 프레임 워크
소프트웨어 신뢰성 공학을 적용할 때에 프로젝트에 대해 너무 자세한 정보를 모두 유지하려는 생각은 버려야한다. 많은 사람들이 정확하게 정의된 정보 수집의 목적을 알지 못하는 경우가 많다. 그 결과, 노력에 비해서 얻어지는 이익은 미비한 경우가 많이 발생하게 된다.
어떤 조직에서는 얻어진 정보를 분석하는 능력을 고려하지 않은 채 정보 수집에 많은 자원을 투입한다. 이런 이득 없이 낭비되는 시간 및 인력은 제품 개발 기간을 지연시키고, 비용을 초과하게 하는 문제를 야기하는 원인으로 작용할 수 있다.
정보를 수집하는 과정에 대한 프레임웜트를 Lyu는 다음과 같이 정의하고 있다.
(1) 정보 수집 목적을 정확히 정의한다.이것은 성공적인 정보 수집과 이득없는 정보 수집을 구분 짓는 중요한 요소이다. 개발에 참여한 모든 인원들이 신뢰성과 그것을 위한 정보 수집에 대한 이해를 증대 시켜야 한다.
(2) 정보 수집 프로세스에 대한 계획을 세운다.
정보 수집 계획에는 정보 수집 빈도, 정보 수집 인원, 수집 정보 종류 및 형태, 정보 수집 및 저장 방법, 정보 수집과정 모니터링, 정보 수집 절차, 정보 수집 할당될 자원 등을 포함한다.
(3) 정보 수집 과정에 도움이 되는 도구들을 찾고, 그 도구의 가용성, 사용성 등을 평가한다.
(4) 정보 수집에 참여하는 인력에게 도구의 사용법과 수집될 정보의 종류, 수집 방법에 대한 교육을 한다.
(5) 프로토타입을 개발하는 과정에 정보 수집 프로세스를 도입을 시도하여, 여러 문제를 미리 파악해서 해결함으로 정보 수집 과정에서 발생할 수 있는 자원의 낭비를 미연에 방지한다.
(6) 계획을 실행한다.
계획된 자원을 실제로 할당하는 것이 중요하다.
(7) 정보 수집이 계획과 목적에 맞게 이루어지고 있는지를 모니터링한다.
(8) 정기적으로 정보를 분석한다.
너무 늦게 정보를 분석해서 인도된 후에 신뢰성을 추정하는 것은 신뢰성 추정으로 얻을 수 있는 많은 이득을 놓치게 된다.
(9) 정보 수집 과정에 대해서 가능한 빨리 모든 정보 수집에 참여하는 인력에게 피드백을 준다.
이 과정을 통해서 참여 인력은 정보 수집의 영향력을 실제적으로 인지할 수 있어 더욱 더 동기 부여를 받게 된다.
2. 신뢰성 모델
소프트웨어 신뢰성의 정의를 다시 한 번 살펴보면, “특정 시간 동안 정해진 환경 조건하에서 요구되는 기능을 고장 없이 수행할 확률”이다. 이 정의에 의해서 신뢰성은 운용상의 고장의 빈도에 의해서 좌우되는 것을 알 수 있다. 고장이 자주 일어나는 시스템은 당연히 신뢰성가 낮은 시스템이다. 하지만 운용 단계에 들어간 시스템의 실제적인 신뢰성를 측정하는 것은 단지 현재 시스템의 신뢰성를 나타낼 뿐 어떤 의미 있는 정보가 될 수가 없다.
보통 신뢰성를 목표를 정하고 그 기준을 만족하는 시스템을 인도하여 사용자가 운용하여야 하기 때문에, 시스템의 운용단계 이전에 신뢰성는 측정되어야 한다. 운용 상태의 고장을 가장 잘 반영하는 것이 시험 단계에서 발견된 결함들이다. 따라서 시험 단계에서 모아진 결함 정보들을 통계적인 방법으로 분석해서 미래의 즉, 운용 단계의 고장의 빈도를 예측할 수 있게 만든 통계적 모형이 신뢰성 모델이다.
시험 단계에서 모아진 결함 정보들을 분석한 패턴은 다음과 같은 특성을 가진다. 시간이 지나면서 시험 단계에서 결함이 발견되면서 제거되어지는 계속적인 작업을 통해서 시스템 내의 결함이 줄어드는 경향을 가지게 된다. 즉, 시스템 내에 내재된 결함의 수가 감소하여 신뢰성가 점차로 증가하게 된다. 고장이 일어나는 간격이 처음에는 매우 좁았지만 시험을 거치면서 결함이 제거됨으로 고장의 간격이 점차로 넓어지게 된다. 이렇게 신뢰성가 점차로 증가하는 모형을 반영한 것이 소프트웨어 신뢰성 성장 모델 (Software Reliability Growth Model: SRGM)이라고 한다.
신뢰성 모델은 입력 값으로 시험에서 얻어진 결함 정보와 시험 이전 단계에서 정량적으로 측정될 수 있는 신뢰성에 영향을 미칠 수 있는 측정치들을 사용하여 결과 값으로 고장 간 시간 (The Time To Next Failure), 남아 있는 결함 수 (The Number Of Remaining Faults), 소프트웨어 신뢰성 함수 (Software Reliability Function), 결함 밀도 함수 (Fault Density Function)와 같이 시험의 지속 여부와 인도 시점에 대한 의사결정의 정보를 산출해낸다. 소프트웨어 개발단계에서의 소프트웨어 신뢰성 평가방법은 초기 신뢰성예측(Early Prediction) 방법과 사후 신뢰성 추정(Late Estimation) 방법으로 나누어 생각할 수 있으며, 이를 그림으로 표현하면 다음과 같다.

[고장율(Failure Rate)와 시점(Time)과의 관계
위 그림에서 시점1-고장율1은 소프트웨어 제품의 구현이 완료된 상태까지를 나타내며 이를 초기신뢰성예측(Early Prediction)단계로 정의한다. 시점2-고장율2는 소프트웨어 시험을 마친 상태를 나타내며 이를 사후신뢰성추정(Late Estimation)단계로 정의한다. 초기신뢰성예측은 소프트웨어 시험의 방향을 결정하며, 사후신뢰성추정에 따라 시험의 종료시점을 결정하고, 앞으로 수행되어야 할 시험 시간을 결정하는데 기반이 되는 정보를 제공한다.
이 두 단계를 비교하면 다음 표와 같다.

[초기 에측, 사후 추정 단계의 비교]
신뢰성 예측모델은 과거 경험적 자료를 기반으로 하기도 하지만 소프트웨어 개발 수명 주기의 수집된 자료를 기반으로 할 수 있다. 다음 그림은 소프트웨어 개발 수명 주기에서 신뢰성 예측과 추정에 대해 표시한 그림이다.
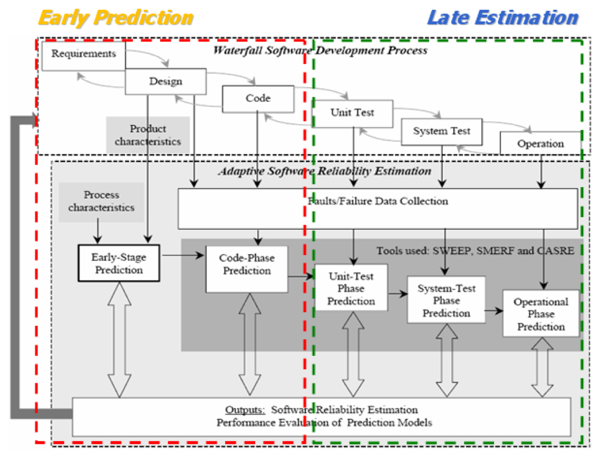
[소프프트웨어 개발 수명 주기에서 신뢰성 예측과 추정]
신뢰성 예측은 신뢰성와 관련된 유용한 척도와 측도를 통해 현재 또는 미래의 신뢰성를 결정하며, 요구사항분석부터 코딩단계까지의 활동과 산출물을 통해 시험 이전단계의 신뢰성를 예측할 수 있다. 신뢰성 추정은 시험/운영 동안에 얻어진 Faults/Failure 데이터를 기반으로 현재의 신뢰성를 결정하며, 신뢰성 목표 값과 비교하여 만족하는 수준에서 테스팅의 중단을 결정 할 수 있고, 신뢰성 목표 값을 달성하기 위해 추가적으로 수행되어야 할 테스팅에 필요한 시간을 예측할 수 있다.
3. 소프트웨어 신뢰성 모델: Prediction과 Estimation 모델
앞의 신뢰성 측정 유형에 따라 신뢰성 모델은 예측모델과 추정모델로 나눌 수 있다. 가장 대표적인 예측모델로는 RL-TR-92-52 모델이 있으며, 추정모델에는 실패시간을 기준으로 하는 Time Domain 모델과 실패 수를 기반으로 하는 Interval Domain 모델이 있다. 예측모델의 대표적인 모델로 RL-TR-92-52 모델이 있으며, 이는 Concept 단계부터 Implementation 단계에서의 중요 요소를 고려하여 초기 결함 밀도를 예측할 수 있다.
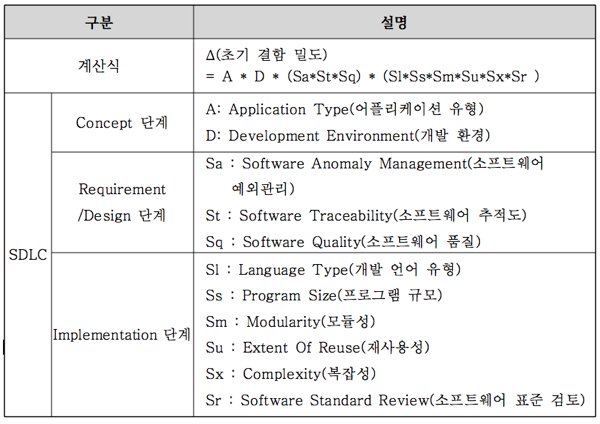
[신뢰성 예측 모델 (RL-TR-92-52 모델)]
추정모델은 시험를 수행하면서 수집된 실패 시간 데이터를 기준으로 하는 Time Domain 모델과 실패 수 데이터를 기준으로 하는 Interval Domain 모델을 이용하여 현재 상태의 신뢰성를 예측할 수 있으며, 이들은 기본적으로 몇 가지 가설을 기반으로 한다. 첫째는 신뢰성 측정을 위한 시험 환경은 실제 운영환경과 동일하다. 둘째는 실패가 일어났을 때 실패의 원인이 되는 결함은 즉시 제거되어진다. 셋째는 결함을 제거하는 과정에서 새로운 결함은 삽입되지 않는다. 넷째는 이들은 임의의 수학적 공식으로 표현되어 진다. 이러한 가설을 기반으로 소프트웨어 실패를 F(T)라는 시간 T의 확률밀도함수(Probability Density Function) F로 정의하여 표현한다. 이들 모델을 신뢰성 추정의 대표적인 툴인 Casre(Computer Aided Software Reliability Estimation)와 Smerfs(Statistical Modeling And Estimation Of Reliability Functions For Software)에서 지원하는 모델을 기반으로 정리하면 다음과 같다.

[신뢰성 추정 모델]
예측모델과 추정모델은 소프트웨어 개발단계에서 사용되는 시기가 다르므로 이들 모델의 입력과 출력에도 차이가 있다. 일반적으로 예측모델은 소프트웨어 개발 환경과 경험 그리고 개발 프로세스의 활동들로부터 수집된 데이터를 기반으로 시험 이전단계에서의 초기 결함밀도와 현재의 신뢰성의 예측이 가능하다. 그리고 추정모델은 시험을 통해 수집된 결함 데이터를 기반으로 해서 고장률 그리고 남아있는 결함 수를 추정하고 목표로 하는 신뢰성를 달성하기 위해 수행되어야 할 시험 시간, 현재의 신뢰성의 추정을 가능하게 한다.
다음 표는 예측 모델과 추정 모델의 입력과 출력을 정리한 표이다.

[예측 모델와 추정 모델의 입력과 출력]
4. 신뢰성 측정 프로세스
일반적으로 소프트웨어 신뢰성 측정 프로세스는 9 단계로 정의된다. 이를 도식화 하면 다음 그림과 같다.

[소프트웨어 신뢰성 측정 프로세스]
첫째로 조직적 전략 계획의 수립이다. 이는 시스템 사용자의 요구사항과 목표를 고려하여 시스템의 신뢰성의 목표와 제약사항을 검토함으로써 이를 달성하기 위한 소프트웨어 제품의 신뢰성 속성들을 식별하는 것이다. 소프트웨어 신뢰성를 관리하고 데이터를 수집하기 위한 계획을 수립하는 것으로 이러한 것들은 문서화된 활동으로 정의한다.
둘째로 소프트웨어 신뢰성 목표를 결정한다. 이는 내부적으로 프로젝트의 계획, 규모, 범위, 비용, 일정을 고려하고, 외부적으로 시스템의 환경과 사용자의 신뢰성 요구수준을 고려하여 납기 될 소프트웨어의 최상의 신뢰성 목표를 결정하는 것이다.
셋째로 측정 프로세스의 구현이다. 이는 다음에 기술될 넷째부터 여덟째까지의 단계를 나타내며 작업환경에 따라 각 단계들은 변경되거나 추가되어질 수 있다. 측정 프로세스의 구현을 위해 고려되어야 할 일반적인 사항들은 다음과 같다.
- 소프트웨어 신뢰성를 최적화하기 위해 데이터의 수집과 측정 활동이 선택되어야 한다.
- 측정에 관련된 사항은 문서화 되어야 하고, 데이터 수집에 대한 요구사항과 각 척도들의 값에 대한 조건이 명시되어야 한다.
- 측정을 수행하고 관찰하기 위한 책임을 할당하며 이를 위해 필요한 자원들이 제공되어야 한다.
- 소프트웨어 신뢰성와 신뢰성 측정을 위한 개념, 원리, 활동들에 대한 훈련자료가 제공되어야 한다.
넷째로 측정치의 선택이다. 소프트웨어 신뢰성의 목표의 달성을 도와줄 측정치들이 식별되어야하며 이것들은 개발 및 지원 환경에 적당한 것이 선택되어야 한다.
다섯째로 데이터의 수집과 측정계획의 수립이다. 측정에 기반이 되는 원시데이터에 대한 결정과 수립된 신뢰성 목표와의 비교를 위한 중간 시점들의 결정, 그리고 데이터의 기록과 정확성의 검증, 계산, 결과의 해석 등에 대한 계획 수립이 필요하다. 원시데이터는 개발 과정에서 발생되는 이벤트들과 관련된 정보 그리고 과거 관련도메인에 대한 경험 데이터 등으로 구성된다.
여섯째로 측정에 대한 관찰이다. 개발이 진행되는 과정에 따라 데이터의 수집과 기록이 시작함과 동시에 측정에 대해 관찰되어야 한다. 이를 통해 현재의 측정이 신뢰성 평가에 적당한지에 대한 평가와 조정이 필요하다.
일곱째로 신뢰성 평가이다. 납기 될 소프트웨어의 신뢰성를 보증하기 위해 신뢰성 목표와의 비교를 통해 현재의 신뢰성를 평가하고 적합유무를 판단한다. 만약 목표로 한 신뢰성를 달성하지 못한 경우에는 계획된 일정과 비용의 한도 내에서 개선되어야 한다. 여덟째로 신뢰성의 목표를 만족한 제품을 릴리즈하고 측정에 대한 효과성과 현재 측정 프로세스에 대한 평가를 수행한다.
마지막으로 측정데이터들은 미래의 프로젝트와 운영단계에서 활용되기 위해 보존되며 이는 신뢰성 측정 프로세스의 개선을 위한 베이스라인으로 활용된다.
본 게시물의 모든 저작권은 본인에게 있으며, 본 게시물의 일부 또는 전체를 인용할 시에는 반드시 출처를 밝혀야 합니다.
'Software Engineering' 카테고리의 다른 글
| Software Reliability Engineering (0) | 2021.01.24 |
|---|---|
| Software Reliability Engineering Process (0) | 2021.01.24 |
| Strategy for Software Reliability Improvement (0) | 2021.01.24 |
| 일반적인 소프트웨어 측도 (Measurement)의 유형 (0) | 2021.01.24 |
| Key Issues in Requirements Reuse (0) | 2021.01.24 |